
随着大数据在人们工作及日常生活中的应用,大数据可视化也改变着人类的对信息的阅读和理解方式。从百度迁徙到谷歌流感趋势,再到阿里云推出县域经济可视化产品,大数据技术和大数据可视化都是幕后的英雄。今天,我们将连载由Teradata独家提供的来自全球28个大数据可视化应用案例。文章中不仅有极具艺术美感的可视化炫图,更有作者为大家解析可视化是如何制作的。
本系列4篇文章为36大数据独家专稿,任何不表明来源36大数据和Teradata以及本文链接http://www.36dsj.com/archives/41214的转载均为侵权。公众号也是如此。
一、航线星云
作者:Karthik Guruswamy

关于洞察
截止到2012年1月,开源网站OPENFLIGHTS.ORG上记载了大约6万条直飞航班信息,这些航班穿梭在3000多个机场间,覆盖了500多条航线。
通过高级分析技术,我们可以看到世界上各家不同的航空公司看起来就像是一个美丽的星云(国际星云的组成部分)。同种颜色的圆点和粗线提供了见解,它们代表提供相同航线的航空公司,显示出它们之间的竞争以及在不同区域间的潜在合作。
这张基于数据可视化的Sigma图表显示了服务城市相似的不同航空公司。图中的圆点或圆圈代表航空公司,连线的粗细和远近则反映两个航空公司之间的相似性;连线越粗或越短则代表两家航司服务的城市越相似。图表中有几组航空公司,直观地表现了它们所服务的地理区域。
这张图表中的关键洞察当然地是航空公司之间的相似性甚至是重叠,它们是中国的南航和东航、阿联酋航空和卡塔尔航空、英航和汉莎航空、美航和达美航空;我们可以从中看出这些公司之间的竞争关系。瑞安航空则通过服务与汉莎航空和英航存在潜在协力的城市占据了一个利基市场;比起意大利或汉莎等其他的欧洲航司,法国航空则与美国联航等美国航空公司更为相似,这也许可以解释为联合品牌效应。本质上说,这是一张多维的韦恩图,用一种简明扼要的方式揭示了不同主体间的复杂关系。
总的来说,这张图表揭示了不同航司之间的相似性和竞争情况,有利于发掘潜在的合作关系、增加市场份额和市场覆盖面。这项技术可以通过不同参与者之间的相同变量,用于分析任何生态系统。
分析技术
这张可视化图表通过Aster App中心生成,运用到了关联挖掘的分析技术,研究上下文中各条目的共现关系。其中关联挖掘的算法是协同过滤,它作用于航线和城市数据,并将数据当做零售篮子数据。也就是说,篮子代表城市,而航空公司则是条目。两个航司之间的相似性由相似性得分确定,计分的原则是比较各个航司独有的航线以及同时运营的航线。之后再将这些成对的相似性得分当做连线的权重,再把各个航司当做节点,共同输入可视化仪器当中,运用具有模块上色技术的force-atlas算法,最终生成出这张美丽的图表。
二、Calling Circles
作者:Christopher Hillman

关于洞察
我们无论何时何地都在使用手机并且产生出非常大量的资料,这些资料代表了我们每天的行为及活动。我们与其他人的每通电话及简讯都对应到我们的社会关系、商业活动以及更广泛的社群互动并且形成了许多复杂互相联结的通话圈。
这个资料视觉化图表是从行动电话使用者的通话模式资料所制作的。每个点都代表一个使用者拨出的手机号码,愈大的点就代表这个号码被拨打愈多次。每条两点之间的线都代表着从一个号码拨打到另一个号码。
每个行动电话使用者都会有一种独特的通话模式,这种模式可以用来发展适合的话费方案并且可以用来定义或预测他/她的行为。举例来说,当一个使用者正要从现在的行动电话服务商转换到另一个服务商时,我们可以从网内及网外发现两个类似的通话模式。
这张特别的图表是在前期由一连串的分析产生用来过滤第一层的通话模式。这里使用到的资料只从在几秒钟的时间取得。从图表的左上角可以看到许多大回圈,这些回圈表示短时间内这些号码被拨打了许多次。可以推测这些号码有可能是机器,像是自动答录机、互动式语音应答(IVR) 系统、安全系统或警报。人类不可能在短时间拨出这么多电话。这些电话会先放置在一个分开的群组,后续的分析就可以集中在个人使用者的通话模式上。
分析技术
我们利用图表来达成资料视觉化,虽然在调整版面格式的参数与传统展示图表不同。有一个常见的问题就是这些互连的图表通常在短时间就会变成非常巨大且因为庞大的互动次数导致几乎不可能被视觉化。从一个高度连结的图表里选出一段范例是一个困难的问题,因为我们需要决定忽略哪些连结。在这个例子里,我们取用来自非常短的时间的资料来达到一个可以呈现的资料范围。
资料格式就相对简单,拨话号码、收话号码、拨话时间、通话时间。我们先利用机器学习(machine-learning) 来对资料作分群然后再利用Aster Lens 来展示图表。
Calling Circles作者介绍

Christopher Hillman
Christopher Hillman 跟他的妻子及两个小孩住在英国伦敦,在Teradata 的进阶分析团队(Advanced Analytics team) 担任首席资料科学家在全世界旅行工作。
他钟情于分析工作且有二十年的经验于商业智慧(business intelligence) 及进阶的分析产业。在Teradata 之前,Chris在Retail 和CPGN vertical作为一位解决方案架构师(solution architect)、首席顾问及技术总监。 Chris 现在与Teradata Aster 专家一同工作且参与大数据的分析专案,他帮助客户洞察资料中的价值并且了解MapReduce 或SQL 作为合适的技术。
在Teradata 工作的期间,Christopher 也同时攻读在Dundee 大学的资料科学博士并运用大数据分析在人类蛋白类的实验资料上。他的研究领域包含利用平行化演算法即时分析质谱仪的资料。他也在大学开课教授Hadoop 及MapReduce 程式设计。
三、信号风暴骑士
作者:桑德拉.拉曼 (Sundara Raman)
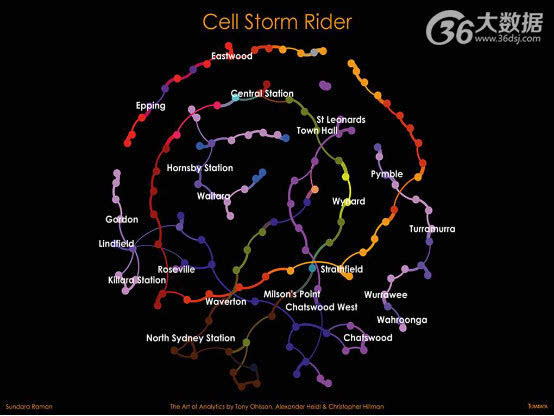
关于洞察
此可视化捕捉了桑德拉.拉曼在澳大利亚悉尼通勤列车廊道的旅程。桑德拉携带其手机和专用软件乘坐列车穿行于悉尼, 由于列车快速穿过城市, 我们可以通过其手机与信号发射塔的连接来跟踪, 用彩点(或节点)描绘在图表上。
利用手机数据对运动中的、聚集大量人群的交通模式进行研究是新分析形式的一部分。其主要目的在于优化发射塔网络、避免性能问题、改善客户体验。但它还能支持新兴数据货币化发展,详细的交通流量信息可用于城市规划、零售商店位置分析和市场营销供应。
桑德拉在分析中探寻能击垮发射塔、影响手机性能的信号“风暴”。当拥挤的通勤列车奔跑于轨道线上,后停于车站,列车发出的100-1000个信号快速移动于各发射塔之间,就足以击垮它们。该可视化是一系列图表的一部分,覆盖了发射塔性能数据、通勤交通流量以及塔切换的信息,准确表现出手机信号的“风暴潮”,从而据此提出详细的建议来优化网络。
图表中还能突显出特定客户体验时由于在4G发射塔(暗点)和低速3G发射塔(亮点)间切换而出现的问题—-信号在发射塔之间来回反复切换,塔信号强度剧烈变化,产生“乒乓效应”。典型代表是位于林菲尔德、可莱雅、怀塔拉、北悉尼以及查茨伍德各车站附近的相连的封闭式发射塔群。
分析方法
该可视化是通过Teradata Aster和Aster Lens实现的。智能手机的遥信数据是从同时使用的3G和4G手机中收集的, 收集在拥挤的公共交通路线上使用专用软件的数据, 地点是沿着澳大利亚悉尼北岸线和史卓菲市交通线一带。分析还包括了对火车站和信号发射塔位置数据的地理空间分析, 从而将位于火车站方圆1公里内的发射塔隔离出来。这个方法有助于衡量确定小范围内,车站周围各发射塔之间信号传播的影响。另外GEXF西格玛图表中还添加了颜色代码, 利用可视化语言统一地区分4G和3G信号发射塔的区域。每种颜色代表一组发射塔的网络覆盖区域。悉尼城市铁路公布的统计数据涉及峰值时间每个车站火车的交通负荷, 分析则利用这一数据关联了手机站点的性能。
作者介绍

桑德拉.拉曼 (Sundara Raman)
桑德拉白天是一位高级电信行业咨询师, 夜间则是一位胸怀大志的数据科学家。他在新西兰梅西大学获得商业管理硕士学位, 现在与妻子及2个孩子住在澳大利亚的悉尼。
桑德拉还是一名发明家, 他曾与他的妻子共同应用“认知行为疗法”(CBT)原则, 设计出“计算机辅助心理评估与治疗”, 获得了澳大利亚一项专利权。
所以, 如果你在下一个日常通勤时碰巧瞥见桑德拉在把玩多个手机, 你就会明白他不是疯了。他只是在利用分析获得深入见解, 从而帮助电信客户改善移动网络的客户体验。
四、互联网络
作者:Yasmeen Ahmad
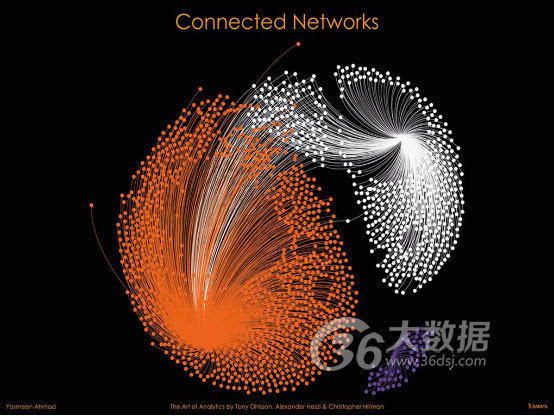
关于洞察
这一匿名可视化报告用于支持一家Telco运营商分析住宅Telco线路。该项目旨在确定线路与网络硬件性能之间的关联,此类关联可能影响到客户体验。
点(节点)代表Telco网络上的DSLAM(数字用户线接入复用器)。DSLAM提供了一项重要服务,能够影响客户呼叫体验;它们可将客户线路连接到主网络。
DSLAM服务级别有多项测量指标,例如衰减、比特率、噪声容限和输出功率,并可针对每条线路整合至三个性能类别。紫色节点显示具备卓越性能的DSLAM,橙色显示具备出色性能的DSLAM,白色显示性能较差的DSLAM。
在图表中,仅少数DSLAM体验到了高质量服务(紫色)。这些 DSLAM 在同一建筑中与主网络基础设施共置,由于靠近中央网络中枢,从而带来了优质服务。大多数客户实现了出色体验(橙色),同时我们发现城市郊区存在服务较差(白色)的DSLAM。
当客户获得可变网络质量时,客户体验和满意度会受到很大影响。Telco的主要目标是确保客户获得一致的体验,即使是那些身处主城市外部的用户也不例外。此图表确定了每个提供可变服务级别的 DSALM;以出色(橙色)和较差(白色)簇之间共享的节点表示。借助这一数据,Telco现在能够调查和优化可变DSLAM。
分析方法
这一西格玛可视化报告使用内建分析和在Teradata Aster平台内发现的可视化创建而成。
收到的数据来自整个城市的住宅线路,其属性包括衰减、比特率等。我们对这些属性进行了整合,以确定表明客户网络体验的性能等级。
这些簇构成了相关性和回归分析的基础,以确定在不同因素下网络性能的变化,这些因素包括:线路技术和长度、调制解调器类型和配置、DSLAM、卡技术、地理位置等。
该西格马可视化图表仅显示了整体分析的一部分,即DSLAM与网络性能间的联系。
作者介绍

Yasmeen Ahmad
Yasmeen是Teradata的最有创意和有见地的数据科学家之一。 Yasmeen在苏格兰长大,她喜欢户外活动,尤其是在苏格兰Munros山和在海上划皮艇。
她在许多国家工作过,包括英国、爱尔兰、荷兰土耳其、比利时和丹麦,她涵盖了金融,电信,零售和公用事业等行业。 Yasmeen专精与企业合作以确定他们的挑战,并将其转化为分析背景。她专注于企业如何利用新的或尚未开发的数据来源,沿着新技术以提高自身的竞争能力的独特能力。
Yasmeen已经与许多分析团队工作,提供领导,培训,指导和实践的支持,提供可操作的见解和经营成果。她使用各种分析方法,包括文本分析,预测建模,归属策略和时间序列分析的发展。她坚信可视化的力量使的在企业用户可以容易进行复杂的沟通。
在Teradata之前,Yasmeen在生命科学行业工作作为数据科学家,建设复杂、多维数据分析管线。 Yasmeen还持有数据管理,挖掘和可视化,这是进行在威康信托中心的基因调控和表达的博士学位。她在国际上发表了多篇论文并在国际会议和活动中演讲。此外,她还在MSc教有关科学数据和商业智能硕士课程。
Yasmeen对于数据分析和可视化有敏锐的热情,通过她的研究中一直好奇地问问题并了解更多信息。这些技能已经允许Yasmeen探索多学科的机会,为她提供了新的无尽的挑战!
五、连续性集装箱修理
作者:Frances Luk

关于洞察
物流集装箱在运输过程中常常会受到损伤,而这些集装箱的修理则依靠世界各地数以百计的供应商来处理。在通常情况下,如果状况不好无法继续使用,受损的集装箱会在被运往下个目的地之前就近修理。我们的客户是全世界最大的一家物流公司,他们希望了解集装箱的修理质量以及各个提供修理的供应商。在进行这项分析之前,客户无法获知集装箱使用寿命当中所发生事件的整体概览。而通过重现每个集装箱使用寿命当中发生的所有事件,我们成功地分析出了集装箱的修理模式。
通过这项分析,客户希望找出因为同一种损伤原因而发生的连续的修理活动,规定这两次修理发生在某一段时间内,或者说第二次修理比预期的时间提前了。这种活动表示早期修理的质量较差,从而造成了第二次的修理。这张桑基图中第一列的方框代表负责第一次修理的国家。
第二列的方框则代表负责第二次修理的国家。从第一列方框直接连到‘结束’框的则代表在第一次修理之后没有再发生修理行为,这是理想的状况;连到第二栏方框的则是意外情况。这张可视化图表让我们的客户得以按地域查看提供修理的供应商,未来还可能在工厂层级继续深钻。
分析技术
集装箱修理活动通过内建的数据装载器从Teradata数据库牵引到了Aster数据库中。我们利用事件序列和模式匹配技术来鉴别连续性修理活动。我们利用这张桑基图来比较不同国家修理工厂的质量,图中的线越粗则表示两个国家共同出现的次数越多。这张图表提供了极佳的整合信息,显示出应该关注于哪个国家,接下去可以利用数据来计算重点关注国家发生第二次修理的相对频率。这张桑基图通过Aster平台中的Aster Lens生成。
作者介绍
Frances Luk
Frances Luk是丹麦哥本哈根团队的一名数据科学家。她从小在香港长大,但某天却决定要去做一些不一样的事情,现在和她的丈夫还有两只可爱的小猫一起在丹麦生活,还拥有哥本哈根大学的硕士学位。在成为数据科学家之前,她曾经用五年时间来开发企业Java应用,并有七年从事银行和物流行业的数据仓库和数据分析的经验,现在负责丹麦和其他北欧国家的跨行业售前和大数据管理PS服务。
Frances对数据科学的热情来源于她强大的技术背景以及她对商业强烈的好奇心。每一比特的数据对她来说都像是一个谜,她喜欢拼凑细节并享受美丽图像产生的那一刻,喜欢看到客户发现未知的洞察时脸上惊叹的表情,这就是她每天工作的功力。
六、集装箱修理波浪
作者:Frances Luk
关于洞察
在通过遍布世界的船舶、卡车、火车进行运输的时候,集装箱时时会受到损伤。损伤情况发生时,集装箱会被运到最近的修理铺里,而这些成百上千个的修理铺散布在世界的各个角落。
我们的客户马士基航运公司希望加强他们对不同修理铺修理质量的了解。过去他们无法在每一个集装箱的层级上对这些数据进行分析,但Teradata Aster平台让马士基航运能够在这个层级调查并分析修理结果,获取有趣的发现、了解它们的模式和趋势,而这是前所未有的。
这张可视化图表中右下方的点代表不同的修理活动,曲线上方的点则表示不同的商品,商品和修理活动之间的连线则代表运输某种商品之后马上发生某种修理活动的频率;连线越粗表示运过某种商品后集装箱发生修理的频率越高。从图中可以看到,最粗的线连接着废金属和底板损伤,也就是说最经常出现的商品和修理类型配对是废金属和集装箱底板修理。
对于马士基航运来说,知道废金属最经常导致破损当然不是什么新鲜事,但采集到的这些数据为将来的分析奠定了强大的基础,(自然可以延伸到考虑比如比起其他货品,是不是更经常要运送废金属)。我们不能完全肯定废金属和底板破损之间的因果关系,但这张可视化图表却突出了问题的规模,建立了马士基航运公司的高级分析团队未来进行更细致的分析时的好的起点。将来的分析工作完成时,最终得到的结果可能就是更差异化的货运定价模型,抵减预计的运后修理成本。
分析技术
集装箱运输和修理活动通过内建的数据加载器从Teradata牵引到Aster当中。通过和马士基航运的ADL(敏捷数据实验室)和AA(高级分析)团队紧密合作,我们确定了适合的途径,用来分析货物和修理之间的关系,并应用模式匹配技术调查连续性运输和修理的模式。
之后我们用sigma可视化工具来展现货物和修理类型之间的关系,这两者在图中表示为实心点,连线的粗细表示共现的次数。初始sigma图通过Aster平台中的Aster Lens生成,现在展现的是优化版本。
作者介绍
Frances Luk,同连续性集装箱修理是一个作者。
七、Terror Report
作者:Kailash Purang

关于洞察
这份资料视觉化是Kailash Purang两部分CIA 报告的第一部分。它展示了进阶分析可以快速地客观地从复杂的文件精炼成简单易懂的视觉化图表。这份图表应该与第两部分的报告(Crown Of Thorns) 一起被检视。
Kailash 刻意挑选了一个具高度政治及情绪相关的主题,这份报告是美国参议院特别委员会研究院针对2001 到2006 年CIA(Central Intelligence Agency) 拘留和审讯程序及审讯拷打的研究。
这是一份相当长的报告,总共从6000 页中有525 页被公开,其中包含特定的政府用词以及在技术文件上会有的专有名词。这是份极端重要的文件以至于少数人可以第一手阅读到并且提供自己的意见,大部分人只能从其他人写的摘要报告接触到。然而像这样泛政治化及情绪性的主题,我们如何确定我们读到的摘要是完全正确且没有其他人的主观意见呢?
简短地来说,这是一个对于测试分析工作是否可以提供一个简单客观的方法来检视报告内容的理想主题。
Kaliash 的第一个视觉化图表”恐怖攻击” 是简单的文字云(word cloud),报告里愈常出现的特定文字在图表上呈现愈大的图形。文字云这样的图表可以很快速被制作,也可以轻易客观被吸收。然而,太粗浅的呈现是它的限制,我们从中可看到关键字,但是并无法从图表中得知任何的细节也无法知道各个主题中间的关联。文字云提供我们一个快速且非常简单的方式来了解报告里的内容。
请接着阅读第二部分“Crown Of Thorrns” 。
分析方法
这份视觉化使用525 页的中央情报局委员拘留及审讯计划报告,这份报告是于2014 年12月9号由美国参议院情报委员会公开发表。
这份图表是使用Wordle 制作的,Wordle 是一个由Jonathon Feinberg发表的文字云制作程式且可以从网站上免费取得。我们可以利用英文里的剔除字(stop word) 来移除低资讯价值的字像”的”跟”了”。制作的图表留下最常出现的字词,读者可以简单地从字词出现的频率得到结论。
作者介绍

Kailash Purang
Kailash 是在Teradata新加坡资料科学家领导人。他也在整个东南亚工作,大部分在印尼支援及领导Teradata在银行及通讯产业客户的服务。
Kailash 有新加坡国立大学经济硕士经济跟统计学学士、新加坡国立大学经济硕士、伦敦大学管理学学士。他在分析领域有长达15年跟产业的经验。
尽管是”出卖灵魂” 投身商业领域,他仍然认为所有这一切的学习和技术的目的是为了让人们的生活更轻松更有趣。为了引进一个有趣的无痛的分析方式,他在业余时间作资料视觉化让每个人都可以从简单的分析应用过程中获益。
作为Teradata资料科学家,他努力使自己的客户实现大数据的全部潜力,使他们的客户可以通过更好的服务和产品受益。
——————
未完待续,明天我们将连载全球最牛的28个大数据可视化应用案例(二)
End.


